Chaos Engineering is the practise of testing a system to increase confidence in its ability to withstand turbulent manufacturing conditions.

Chaos Engineering is an innovative software development and testing procedure that aims to reduce unpredictability by putting complexity and dependability to the test.
Large-scale, distributed software system advancements are changing the game in software engineering. As an industry, we are quick to adopt practises that increase development flexibility and deployment velocity. The goal is to conduct controlled tests in a distributed environment that will help you gain confidence in the system’s ability to withstand failures.
Who Benefits from Chaos Engineering?
Because of the broad range of technology and decisions that Chaos Engineering touches, there may be multiple stakeholders in Chaos Engineering experiments.
Stakeholders from those teams may be involved depending on the domain of the application stack (compute, networking, storage, and application infrastructure) and the location of the targeted infrastructure.
The application development team can test without fear of breaking out of the container if the blast radius is small and can be tested in a running container. Platform engineering teams will most likely be involved if the workload or infrastructure has a larger blast radius (for example, testing Kubernetes infrastructure). The primary reason for choosing Chaos tests and looking for flaws is to provide coverage for the unknown.
Chaos in the Real world:
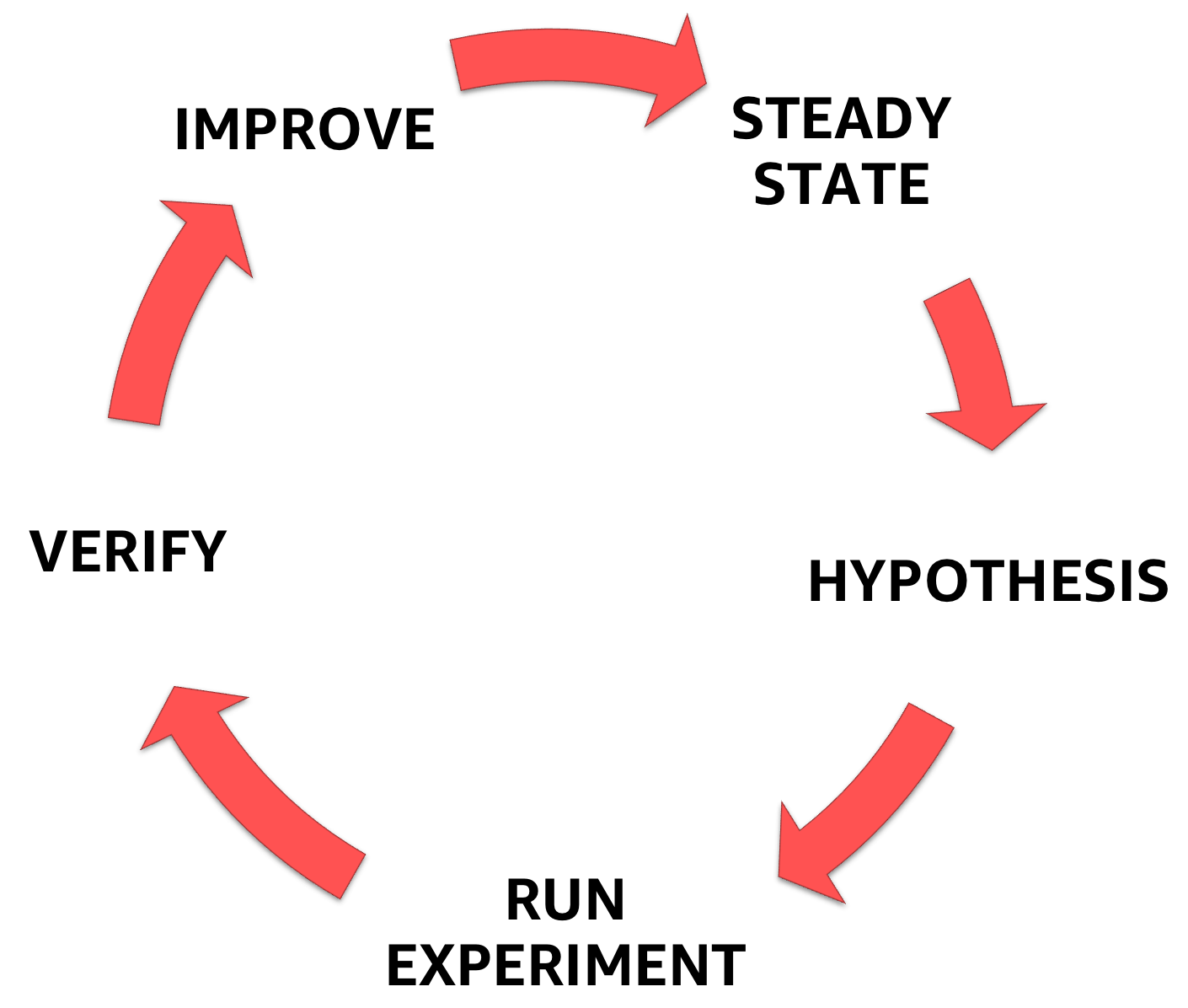
Chaos Engineering can be conceived as the facilitation of experiments to find systemic vulnerabilities to explicitly address the uncertainty of distributed systems at scale. There are four steps to these experiments:
- Begin by defining steady state’ as a measurable output of a system indicating normal behaviour.
- Assume that this steady state will persist in both the control and experimental groups.
- Introduce variables that represent real-world events like servers failing, hard drives failing, network connections breaking, and so on.
- Examine the steady-state differences between the control and experimental groups to see if you can disprove the hypothesis.
Advanced Principles of Chaos Engineering:
The Principles of Chaos Engineering can be defined with four practises that are analogous to the scientific method.
Create a hypothesis based on steady-state behaviour.
Concentrate on a system’s measurable output rather than its internal attributes. Short-term measurements of that output serve as a proxy for the system’s steady state.. Rather than attempting to validate how the system works, Chaos verifies that it works by focusing on systemic behaviour patterns during experiments.
Introduce Variables/Experiments
Chaos Engineering, like any science experiment, introduces variables into the experiment to see how the system responds. These experiments simulate real-world failure scenarios affecting one or more of an application’s four pillars they are compute, networking, storage, and application infrastructure. A failure could be anything from a hardware failure to a network outage.
Continuously run experiments in your pipelines
Software, systems, and infrastructure all evolve over time, and their state/health can shift dramatically. Your CI/CD pipeline is a good area to run an experiment. When a change is made, CI/CD pipelines are started. There’s no better moment to assess a change’s potential impact than when it’s just getting started on its confidence-building journey through a pipeline.
Execute Experiments in Production
As terrifying as the prospect of testing in production is, it is the environment in which users operate, and traffic spikes and load are real. Running Chaos Engineering experiments in a production setting will provide the critical insights to properly test the robustness/resilience of a production system.
Tools for Chaos Engineering
There has been a lot of progress and tooling in the field of Chaos Engineering. The Awesome Chaos Engineering list is a fantastic resource. The chaotic testing tools help to build Chaos Engineering, and new platforms which make Chaos Engineering more accessible.
ChaosBlade
ChaosBlade works with a variety of platforms, including Kubernetes, cloud platforms, and bare-metal, and offers a variety of attacks, such as packet loss, process killing, and resource consumption.
Chaos Mesh
Chaos Mesh is a Kubernetes-native tool for using and managing experiments as Kubernetes resources. It’s also a project in the Cloud Native Computing Foundation’s (CNCF) sandbox.
Litmus
Litmus is a CNCF sandbox project as well as a Kubernetes-native tool. It was designed to test OpenEBS, an open source storage server for Kubernetes.Litmus Probes is a health monitoring feature that allows you to monitor the health of your application before, during, and after an experiment. To check the state of your environment before rolling a research, probes can run shellcode, send HTTP requests, or run Kubernetes commands. This can be useful for automating error detection and stopping an experiment if your systems are unstable.
Conclusion
Chaos Engineering is a useful method that is transforming the way software is built and maintained at a few of the biggest companies. Whereas other methods focus on speed and flexibility, Chaos focuses on the systemic unpredictability that exists in these networked systems. The Principles of Chaos give you the assurance you need to experiment at huge sizes and deliver clients with the high-quality experiences they want.
At Keleno we use Chaos Engineering in various applications, as we are moving more and more towards microservices architecture, so Practising Chaos engineering is becoming very essential
The outcome of chaos engineering brings new knowledge about the system that even developers or testers might not be aware of.
Also in keleno Chaos Engineering is very helpful in validating API Integration.
Gremlin can help APIs in almost every case, even if it’s just to test the resources that underpin the API system.
Here chaos Engineering acts as a solution for cloud computation, distributed system, and microservices system failure which are harder to predict earlier.
Reference: https://harness.io/blog/chaos-engineering/
Image credits: https://www.knowledgehut.com/blog/devops/chaos-engineering
